데이터베이스 선택 가이드
1.KEY-VALUE Delete
-데이터를 키-밸류로 저장하는 데이터베이스
-실용성이 떨어지고, 서브DB로 사용.
Redis:특이하고, 많이 사용.
데이터를 보통 하드디스크에 저장하는데 Redis는 RAM에 저장한다. RAM에 저장하기에 속도가 빠르다는 장점.
메인 DB를 RAM에 복사하고, 필요한 데이터를 RAM에서 꺼내서 사용.
2. RDBMS
-데이터를 표 형태로 저장하고 싶을 때, 관계형 데이터베이스를 사용한다.
어떻게 데이터를 저장할 지 이름(속성)을 작성하고, 데이터를 저장.
-다양한 분야에서 사용할 수 있어서 RANK에 상위권은 모두 RDBMS
-RDBMS는 데이터를 저장하고 싶으면, SQL을 사용한다.
-하지만, RDBMS는 데이터의 중복을 싫어해요.
그래서 반드시 지켜야하는 것이 정규화입니다.
-데이터가 중복되면 다른 테이블로 옮겨요.
-정규화 진행 > 데이터를 조회하는 문법이 어려워지고, 복잡해짐.(단점)
-장점:기본적으로 트랜잭션(나중에 함)을 가지고 있어서, 돈거래
-데이터의 입출력 속도보다는 정확도가 중요한 서비스를 만든다면, 일반적으로 RDBMS를 선택한다.
3.Graph Database
-GraphQL 언어 사용해야함
-SNS의 친구 관계도, 전염병 전염되는 지도, 항공기 노선 등
4. Document Database
-관계형 데이터베이스보다 자유롭다.
-폴더를 하나 만들고, 폴더 안에 Document라는 파일을 만들어서 데이터를 JSON형태로 저장한다.(이름:JEONG 나이:20)
-어떤 데이터를 저장할지 속성을 미리 지정할 필요가 없다.
예) 기존 구조:이름 나이
이름 나이 주소
구조가 변경되어도 에러가 발생하지 않는다.
-데이터의 중복을 제거하지 않아요.
-정규화 없어요.
-DB의 정확도가 떨어질 수 있다.
5.Column-famaily Database
-관계형DB와 같이 표 형식으로 데이터를 저장하고 싶어요. 그런데 유연하게 사용하고 싶어요.
-똑같이 테이블을 만들고, ROW를 만드는데, 데이터의 삽입이 자유롭다.
-행마다 컬럼이 달라도 무관하다.
-단, 데이터의 입출력 하려면, SQL을 사용하지 않고, 자기들이 만든 언어를 사용해야한다.
-정규화를 안한다. > 데이터의 중복을 허용한다.
-장점: 데이터 입출력 쉬워요. 분산 처리 용이, 많은 양의 데이터입출력을 감당해야하는 경우.
6. Search engin
-index를 보관하는 용도로 사용한다.
-빠른 검색을 위한 목차의 역할
-검색이 중요한 사이트를 만들때, 사용한다.
======================================
SELECT
-우리가 가장 많이 사용.
연산자
-숫자만 비교할 수 있다? (X) 아니다
-문자 비교 가능하다.
SELECT
-데이터베이스 내 테이블에서 원하는 데이터를 추출하는 명령어.
-SELECT를 잘 사용해야 데이터베이스를 잘 활용할 수 있다.
기본 구문
SELECT
조회하려는_열_이름
FROM
테이블_이름;
실행 순서
FROM ~ SELECT
SELECT
회원_이름
회원_주소
FROM
회원_테이블;
1.city table > name, countycode, popul 조회.
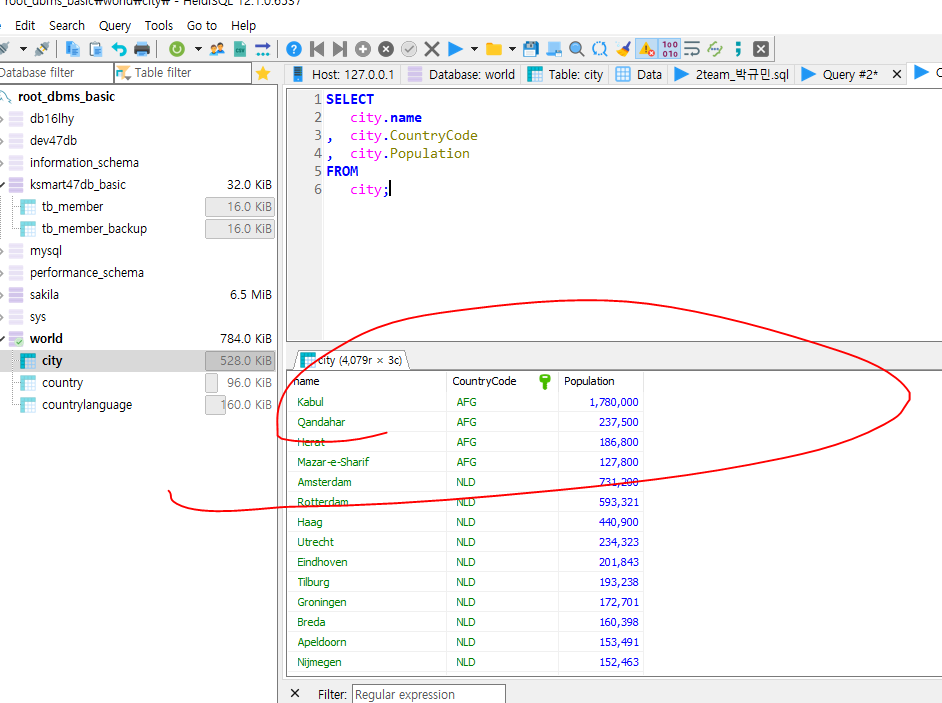
AS(alias):가명
-원하는 이름을 붙일 수 있다.
-생략은 가능하다.
-열의 이름이 길어지는 경우, 별칭을 사용하면 좋다.
-테이블 이름, 열 이름, WHERE절 사용 가능.
-길어서 보기 힘든 컬럼, 계산식이 복잡한 컬럼에 별칭을 사용하면 좋다.
-별칭 사용 시, 작은 따옴표를 사용하는 것을 권장한다.
WHERE
-조건을 지정하는 where절
-조회하려는 결과에 특정한 조건을 줘서 원하는 데이터만 보고 싶을때 사용한다.
-WHERE절 없이 조회하면, 모든 데이터를 조회(테이블의 모든 행)
기본형식
SELECT
조회하려는_열_이름
FROM
테이블_이름
WHERE
조건;
실행순서
FROM~WHERE~SELECT
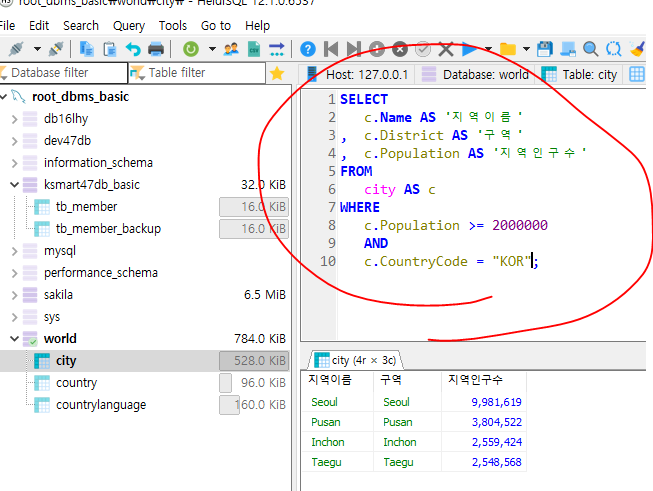
2.City Table > countryCode USA인 NAME, popul 조회(AS, WHERE)

인구수가 200만이면서 국가코드가 KOR인거를 찾아 NAME, District, Population이 뜨게 하시오
===============================================
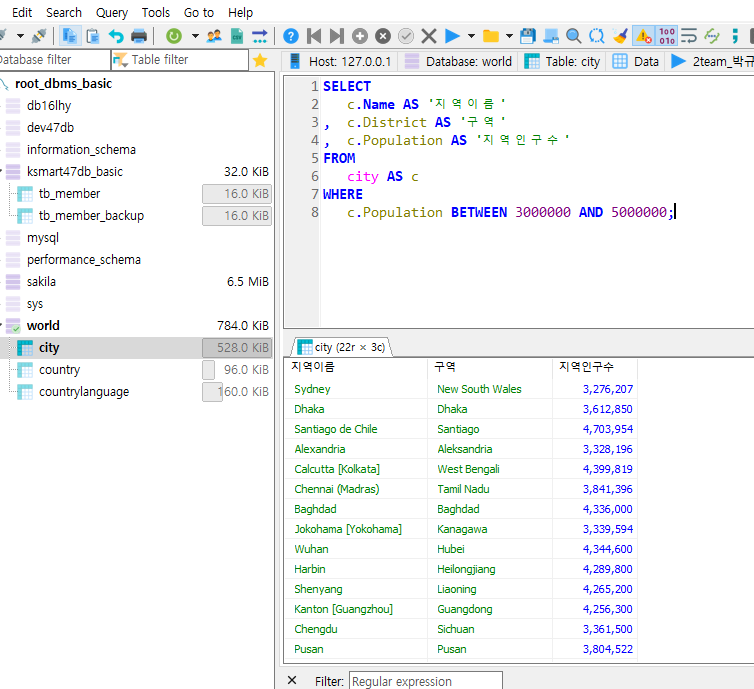
Between ~ And
-범위를 지정한다.
인구수가 300만 이상이면서 500만명 이하*전체
집합, IN()
CountryCode KOR 또는 USA 또는 NLD
전체 조회
문자열의 내용을 검색하는 LIKE연산자
-LIKE키워드를 사용하여 문자를 필터링한다.
-%기호는 그 자리에 어떤 값이 들어와도 상관없다는 의미.
예시)
LIKE'한국%' ->한국으로 시작하는 문자열을 찾는데, 한국A(A한국은 안찾아짐)
1.예) 이 라는 성으로 시작하는 회원 조회
%이%
이%
%이
2.예) 시작은 "이", 끝은 "영" 이면? LIKE'이%영'
LIKE'%한국%' ->앞 뒤에 어떤 문자열이 와도 상관없는데, 한국이라는 단어가 들어간 문자열을 검색.
2)LIKE 심화
LIKE'한국__'(언더바 3개)
->5글자 탐색, 한국ooo
LIKE'_국'(언더바1개)
->2글자 탐색, o국
아이돌 그룹 테이블
_핑크
블랙
에이핑크
특정 문자 제외 탐색
LIKE'a%' -> a +아무 문자열
NOT LIKE'a%' -> a로 시작하지 않는 +아무 문자열
====================================================
중복을 제거하는 DISTINCT
-SQL은 기본적으로 중복을 제거하지 않아요(조회 했을때)
DISTINCT는 하나의 ROW를 기준으로 전체 칼럼을 비교한다.
====================================================
LIKE 실습
1) city테이블에서 국가 코드가 K,U,A로 시작하는 NAME을 조회하시오.

LIKE는 한번쓰면 끝임! 다시 한번 써줘야함 다 각각씩
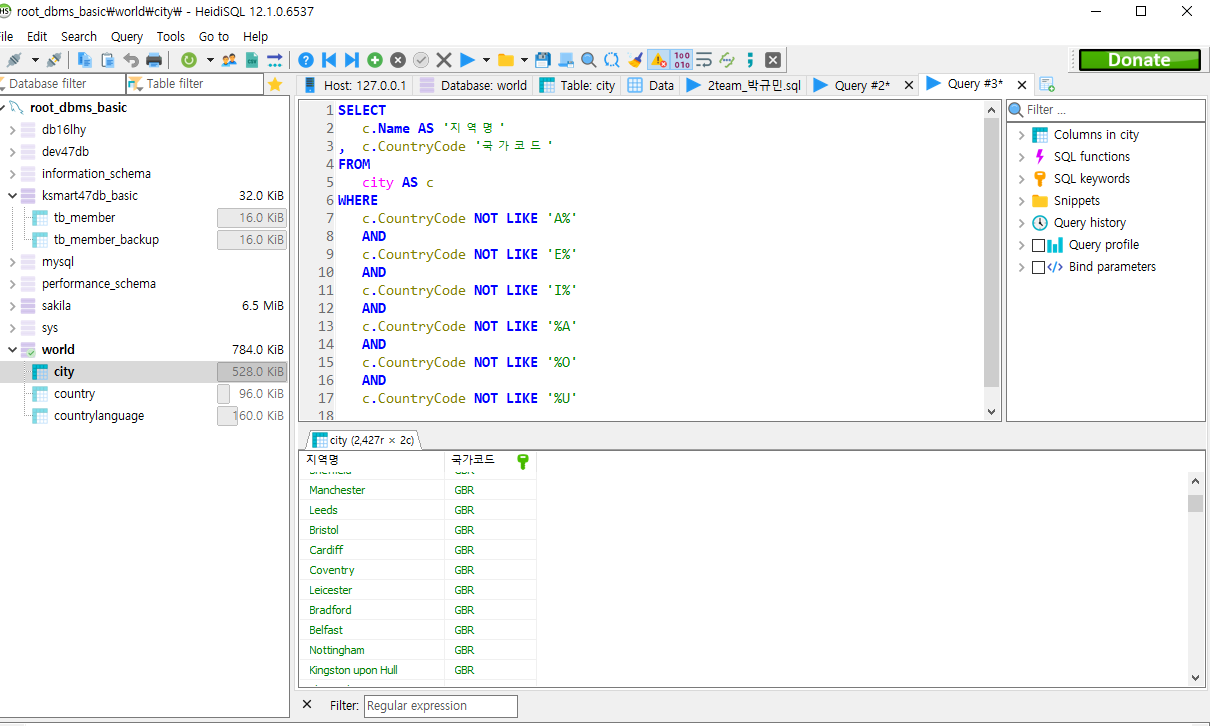
2)NOT LIKE 사용하는 실습
city 테이블에서 국가 코드가 a,e,i로 시작하지 않고, a,o,u로 끝나지 않는 국가의 name과 countrycode를 조회하시오.
==================================================
조회되는 개수를 제한하는 LIMIT
LIMIT 숫자;
LIMIT 0, 100;
==================================================
데이터를 정렬하는 ORDER BY
-SELECT ~FROM ~ WHERE 핵심 구문
-부가적으로 출력결과에 대해 중복 제거, 출력 개수 제한, 데이터 정렬 가능하다.
-기본:오름 차순(기본값)
-내림 차순: DESC(Descending)
-위치 : SELECT ~ FROM 다음에 ORDER BY 위치
->인구수 정렬, 조회: NAME, POPUL
ASC, DESC
->인구수 정렬, 인구수가 100만명 이상, 조회:
NAME, Popul
조건 추가 시, WHERE절 사용.
위치; ORDER BY보다 WHERE이 먼저 나와야함.
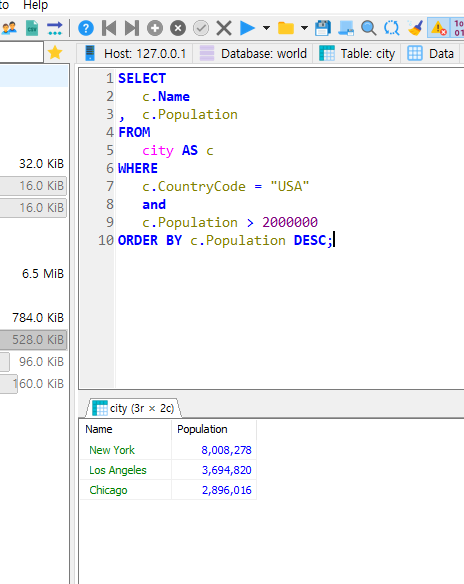
>city table countryCode = USA, 인구 200만명 초과인 NAME, Population조회해보시오.
조회한 값을 내림차순으로 정렬하시오.
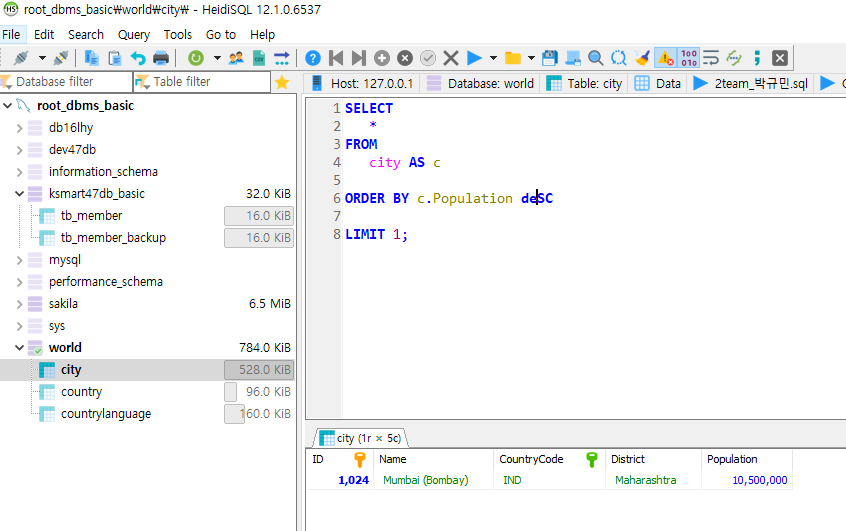
>city table에서 인구수를 조회 후, 가장 큰 값 1개만 조회하시오.
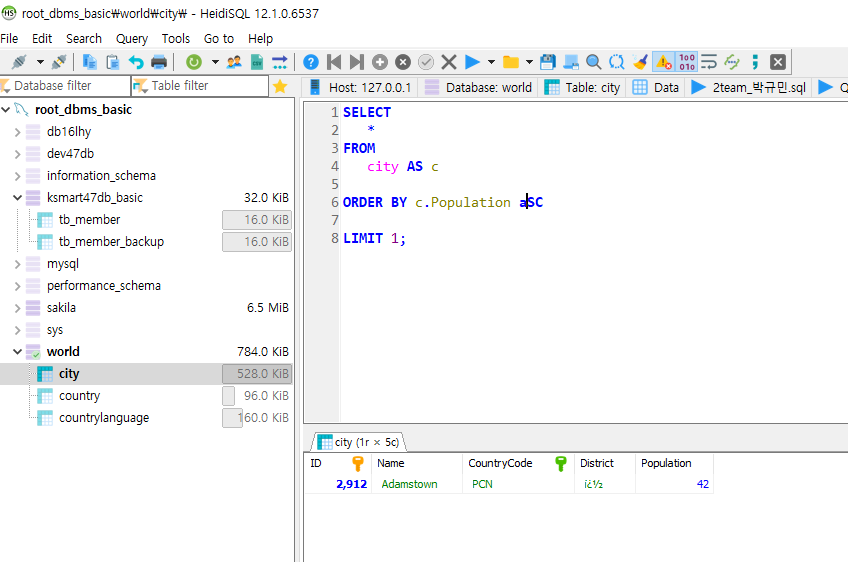
>city table에서 인구수를 조회 후, 가장 작은 값 1개만 조회하시오.
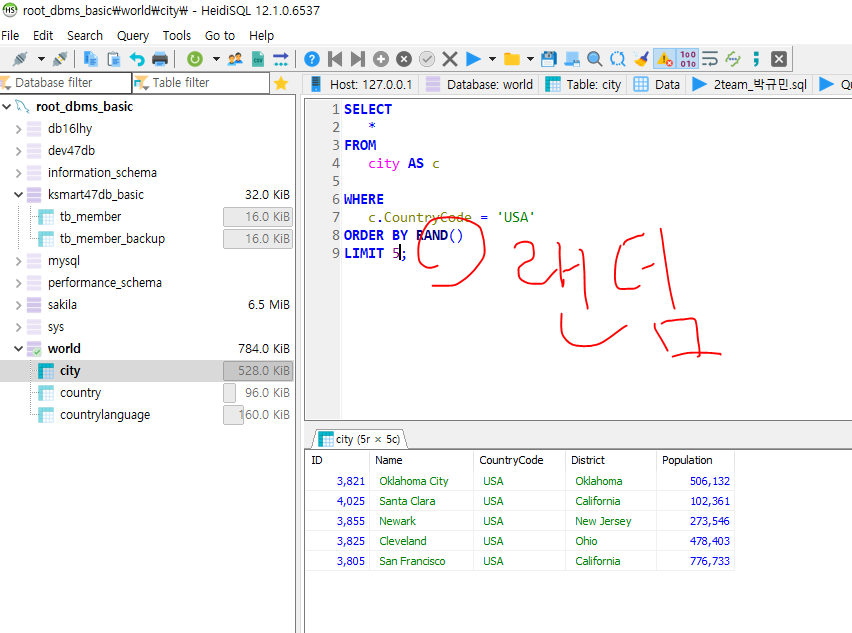
>countryCode KOR, 인구 내림차순 정렬 10개를 조회하시오

정렬 랜덤
-아무 조건 없이 ORDER BY를 사용하면, PK순서대로 정렬한다.
-RAND()함수를 사용하여 랜덤 출력 가능.
ORDER BY member_addr,memebr_name
->주소
=================
GROUP BY와 Aggregate function(집계 함수)
기본 구문
SELECT:열_이름
FROM: 테이블_이름
WHERE: 조건식
GROUP BY:그룹_지을_열_이름
HAVING: 조건식
ORDER BY: 정렬_열_이름
LIMIT: 숫자;
GROUP BY
-그룹으로 묶어주는 역할
-속성 값이 같은 값끼리 그룹을 만들 수 있다.
-HAVING으로 그룹 출력 조건식을 작성할 수 있다.
full group by 에러 속성
1.root접속
2.쿼리문 작성, 실행 후, 종료
group by는 방을 만드는것.
수학 여행 전국 직업훈련 기관 연합
전주
전주-효자동 100명
전주-송천동 50명
전주-삼천동 34명
전주라는 방을 만들어서 (group by)
sum(100 50 34)
서울
대구
대전....
집계 함수
종류
-함계를 구하는 SUM
-평균을 구하는 AVG
-최솟값, 최댓값 MIN(), MAX()
-행의 개수를 세는 COUNT()
COUNT()
=테이블 모든 행의 개수를 센다.
또는
특정 컬럼의 개수를 세고 싶을때,
값이 동일한 이유는 우리 테이블에 NULL값이 없다.
COUNT에 특정 컬럼명을 작성하면, NULL제외
COUNT(*) -> NULL포함.
COUNT와 DISTINCT 함께 사용하기

==================================
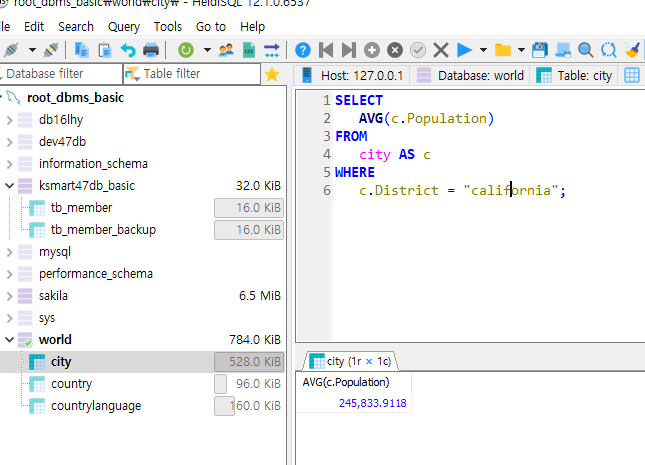
city 테이블에서 district california의 인구 평균을 조회하시오.
*GROUP BY안함
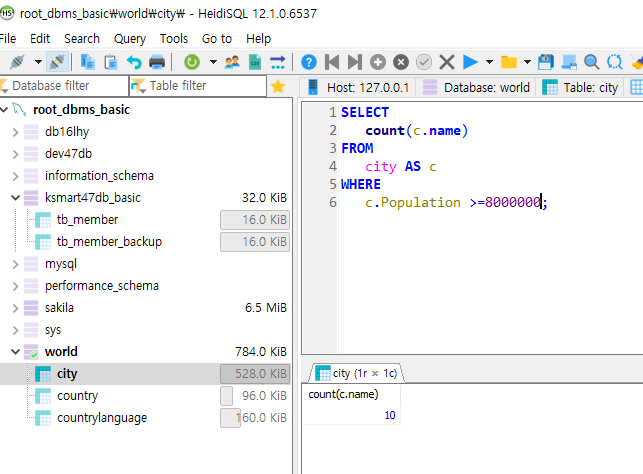
>city테이블에서 인구수 800만 이상인 name의 개수를 구하시오.
*GROUP BY안함
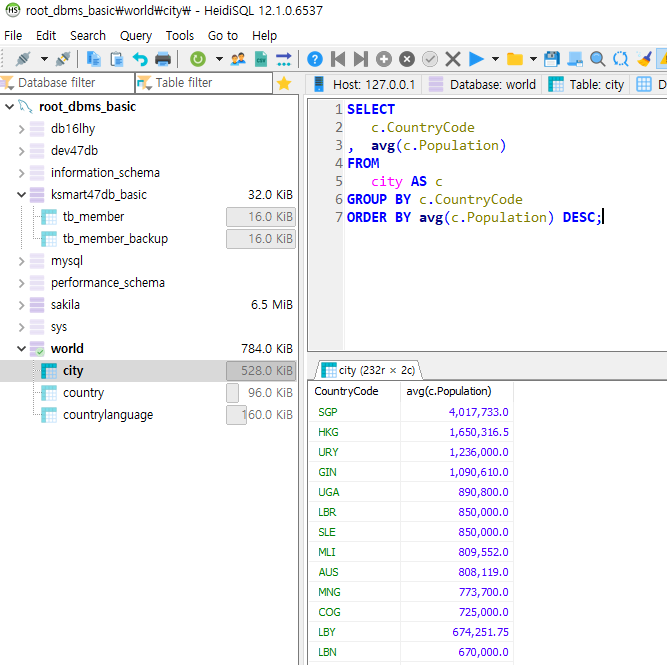
>지역 별 평균 인구를 구해보세요.
조회할 컬럼: countryCode, 평균 인구
*CROUP BY 사용

**GROUP BY 사용했으면, 그룹 대상 컬럼을 SELECT에 조회해줘야함.
조회 후, 평균 인구수 기준으로 ORDER BY ㄱㄱ
==================================
GROUP BY의 결과에 대한 조건을 제한하는
GROUP BY에 조건을 걸고싶을땐 WHERE 대신에 "HAVING 절"을 쓴다!!!!
==========================
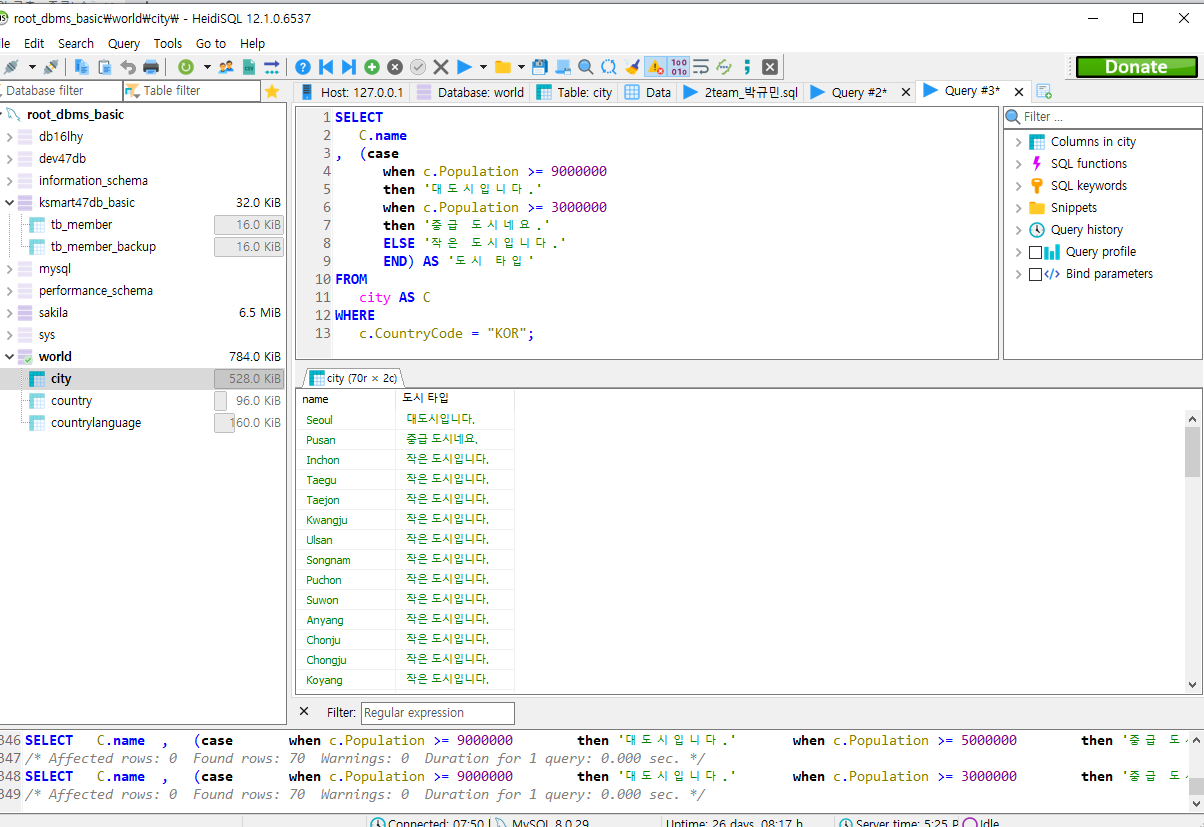
CASE ~ WHEN ~THEN ~ ELSE END
-WHEN과 THEN은 한 쌍이다.
-WHEN과 THEN은 여러 개 존재할 수 있다.
-ELSE를 사용하여 조건에 맞지 않을 떄, 출력할 값을 작성할 수 있다.
'코딩 국비수업들으며 느끼는점' 카테고리의 다른 글
| 개체(Entity)/속성(Attribute)/기본 키(Primary Key)/외래 키(foriegn Key) (0) | 2023.05.16 |
|---|---|
| 데이터 모델링/MySQL 변수 (0) | 2023.05.15 |
| 데이터베이스의 구축 절차 (0) | 2023.05.08 |
| 부트스크랩 (0) | 2023.04.28 |
| 데이터베이스:tb_user테이블작업\34단계jsp_java_DTO_DAO_delete처리 (0) | 2023.04.17 |


